关键词:Context Engineering; Agent Mode; ReAct; Plan and Execute; Reflection
JavaGuide Agent学习链接
Context Engineer
上下文工程,曾经也叫提示词工程,因为上下文的概念拓展,现在包括了各种动态信息挂载技术、记忆折叠等等手段,所以现在一般被称为上下文工程。
上下文工程(Context Engineering)远不止是写 System Prompt。如果说大模型是 Agent 的 CPU,那么上下文工程就是操作系统的内存管理与进程调度。它的核心目标是在有限的 Token 窗口内,以最低的信噪比和成本,为模型提供最精准的决策决策依据。
作者将上下文工程分成三个核心模块
- 静态规则的结构化编排
- 这里规定了系统提示词的编写规范。使用高度结构化的md格式强制划分出:[Role] 角色设定、[Objective] 核心目标、[Constraints] 严格约束、[Workflow] 标准执行流 以及 [Output Format] 输出格式。
- 动态信息的按需挂载
- 工具检索与懒加载:比如面对数百个 MCP 工具时,先通过向量检索选出最相关的 Top-5 工具定义再挂载,避免工具幻觉并节省 Token。
- 动态记忆与 RAG:通过滑动窗口管理短期记忆,利用向量数据库检索长期事实,并将外部执行环境的 Observation(如 API 报错日志)进行摘要脱水后实时回传。
- Token 预算与降级折叠机制
- 对记忆进行优先级划分,低优先级可折叠(早期对话历史压缩摘要),中优先级可精简(RAG检索到的背景资料二次裁剪,只保留核心段落),高优先级绝对保护(系统约束Constraints和当前核心工具Tools描述绝对不能丢失)。
AI Agent核心范式
是Agent工作的流程或者模式,一种比较典型的Agent范式是ReAct,Reasoning + Acting。ReAct论文是2022年发表的,原文链接《ReAct: Synergizing Reasoning and Acting in Language Models》。
ReAct
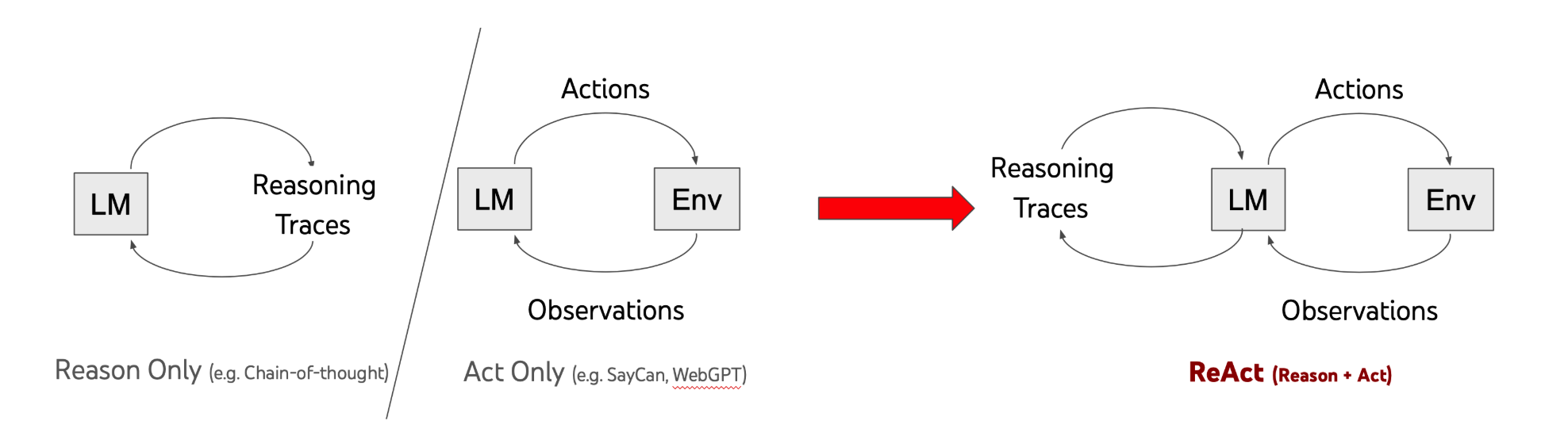 这是一个基于反馈闭环的交替过程,主要包含以下三个核心步骤(Reasoning -> Acting -> Observation),循环往复直至任务完成或触发终止条件:
这是一个基于反馈闭环的交替过程,主要包含以下三个核心步骤(Reasoning -> Acting -> Observation),循环往复直至任务完成或触发终止条件:
- Reasoning:根据当前上下文,使用大模型进行推理,生成决策。
- Acting:根据决策,执行具体的操作。
- Observation:将操作结果反馈给大模型,更新上下文。
优缺点:
- 优势:显著减少幻觉(引入外部真实数据验证)、提升复杂任务的成功率、具备极高的可解释性与可调试性(完整的推理轨迹清晰可见)。
- 局限性:多轮循环迭代会导致系统整体响应延迟增加,同时其表现高度依赖所集成的外部工具和 Skills 的质量与稳定性。
使用ReAct模式进行慢接口问题排查的例子 
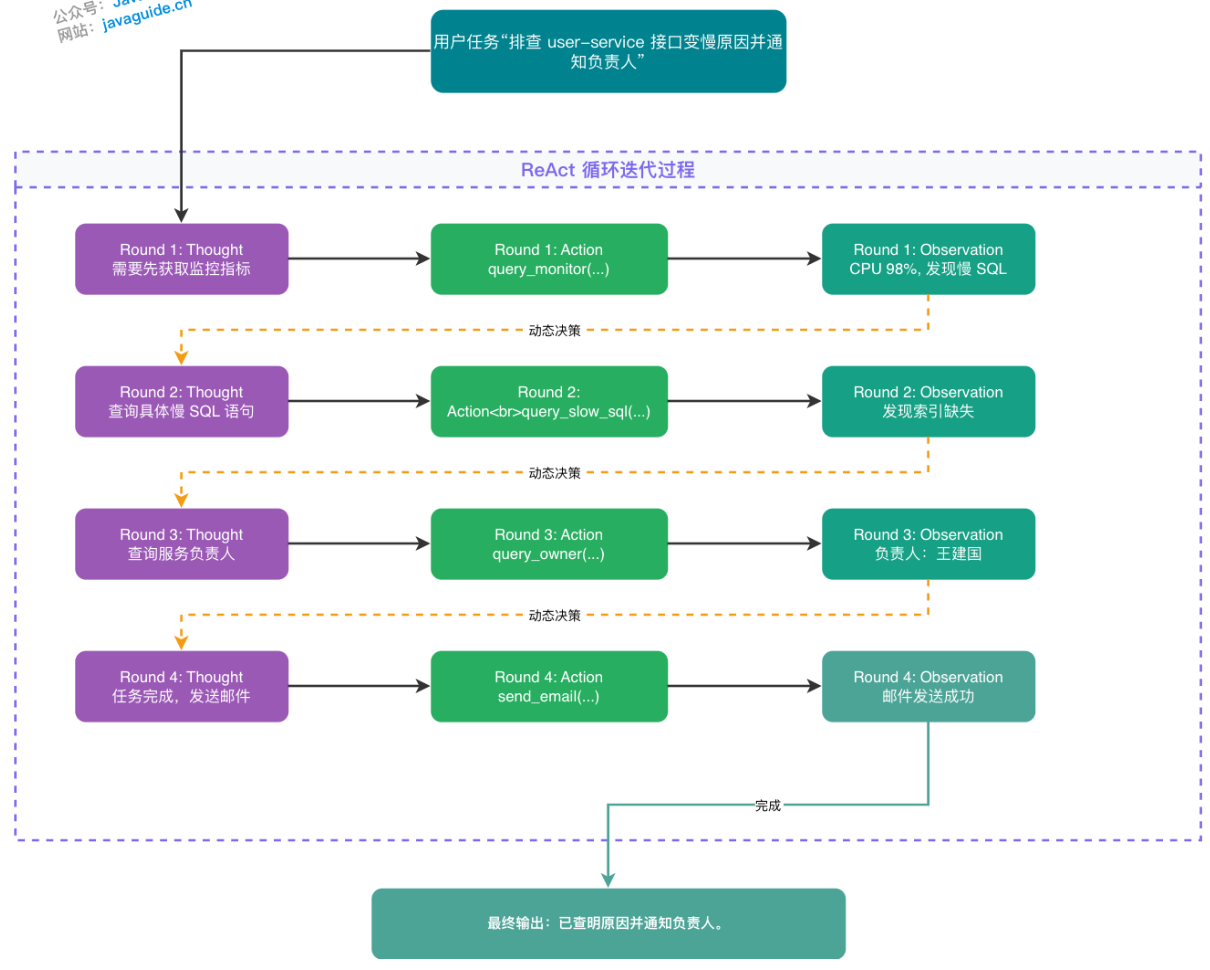 在这些步骤中有些步骤可以聚合成SKILL,例如将2,5步骤对监控和日志进行联合查询,封装成一个diagnose_service_performance的skill,自动编排查监控->查慢SQL->分析瓶颈的调用序列,返回一份结构化的诊断报告,这样就不用每次都拆解成多个独立的步骤,降低了上下文占用,同时保证了在同一种场景下的处理问题的一致性和复用效率。
在这些步骤中有些步骤可以聚合成SKILL,例如将2,5步骤对监控和日志进行联合查询,封装成一个diagnose_service_performance的skill,自动编排查监控->查慢SQL->分析瓶颈的调用序列,返回一份结构化的诊断报告,这样就不用每次都拆解成多个独立的步骤,降低了上下文占用,同时保证了在同一种场景下的处理问题的一致性和复用效率。
Plan and Execute
让 LLM 充当规划者,先制定全局的分步计划,再由执行器按步骤逐一完成,而非“边想边做”。
- 优势:非常适合步骤繁多、逻辑依赖明确的长期复杂任务,能有效避免 ReAct 模式在长任务中容易出现的“迷失”或”死循环”问题。例如,在处理多阶段项目管理时,先输出完整计划(如步骤1: 收集数据;步骤2: 分析;步骤3: 生成报告),然后逐一执行。
- 缺点:偏向静态工作流,执行过程中的动态调整和容错能力较弱。如果环境变化(如工具失败),可能需要重新规划,导致效率低下。
- 最佳实践:两者并非互斥,可结合使用——规划阶段采用 CoT 生成全局步骤,执行阶段在每个步骤内嵌入 ReAct 子循环,兼顾全局结构性和局部灵活性。在执行层,还可以为每类子任务预注册对应的 Skill,让规划出的每一个步骤都能高效映射到可复用的能力模块上,进一步提升执行效率。
例如,在使用Trae的时候,agent会先计划一个整体步骤,在步骤中再使用ReAct模式进行执行。 在我需要添加多进程下载模块任务中,Trae agent先规划了一下步骤。  在步骤三内部还会使用ReAct模式进行执行。
在步骤三内部还会使用ReAct模式进行执行。 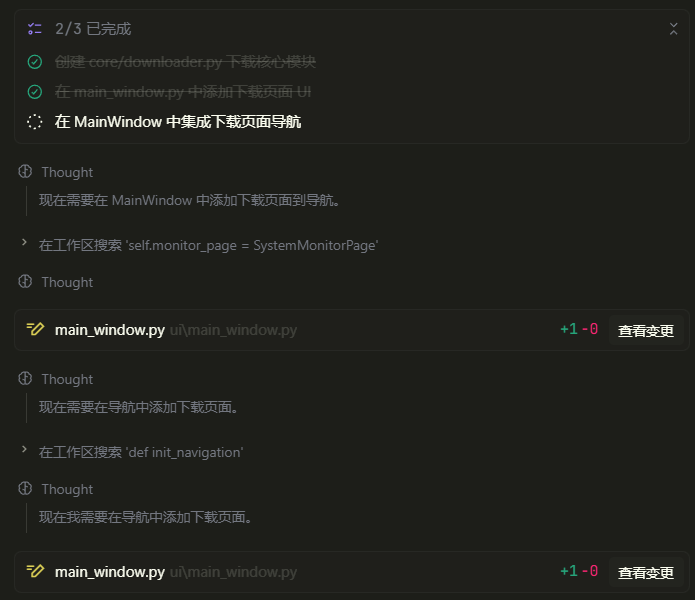
Reflection
Reflection(反思)模式赋予 Agent 自我纠错与迭代优化的能力,核心理念是:通过自然语言形式的口头反馈强化模型行为,而非调整模型权重(即零训练成本)。
三大主流实现方案:
- Reflexion 框架(Noah Shinn et al., 2023):Agent 在任务失败后进行口头反思,将反思结论存入情节记忆缓冲区,供下次尝试时参考。例:代码调试中,上次失败后反思”变量 count 在调用前未初始化”,下次直接规避同类错误。
- Self-Refine 方法:任务完成后,Agent 对自身输出进行批判性审查并迭代改进,平均可提升约 20% 的输出质量。流程:生成初稿 → 自我批评(”内容不够具体”)→ 修订输出 → 循环至满足质量标准。
- CRITIC 方法:引入外部工具(搜索引擎、代码执行器等)对输出进行事实性验证,再基于验证结果自我修正,相比纯内部反思更具客观性。
Reflection 通常不单独使用,而是作为增强层叠加在 ReAct 或 Plan-and-Execute 之上:ReAct + Reflection 使每轮观察后不仅更新行动计划,还进行显式自我反思,形成自适应 Agent。实际应用中显著提升了 Agent 在不确定环境下的鲁棒性,但会带来额外的 LLM 调用开销。
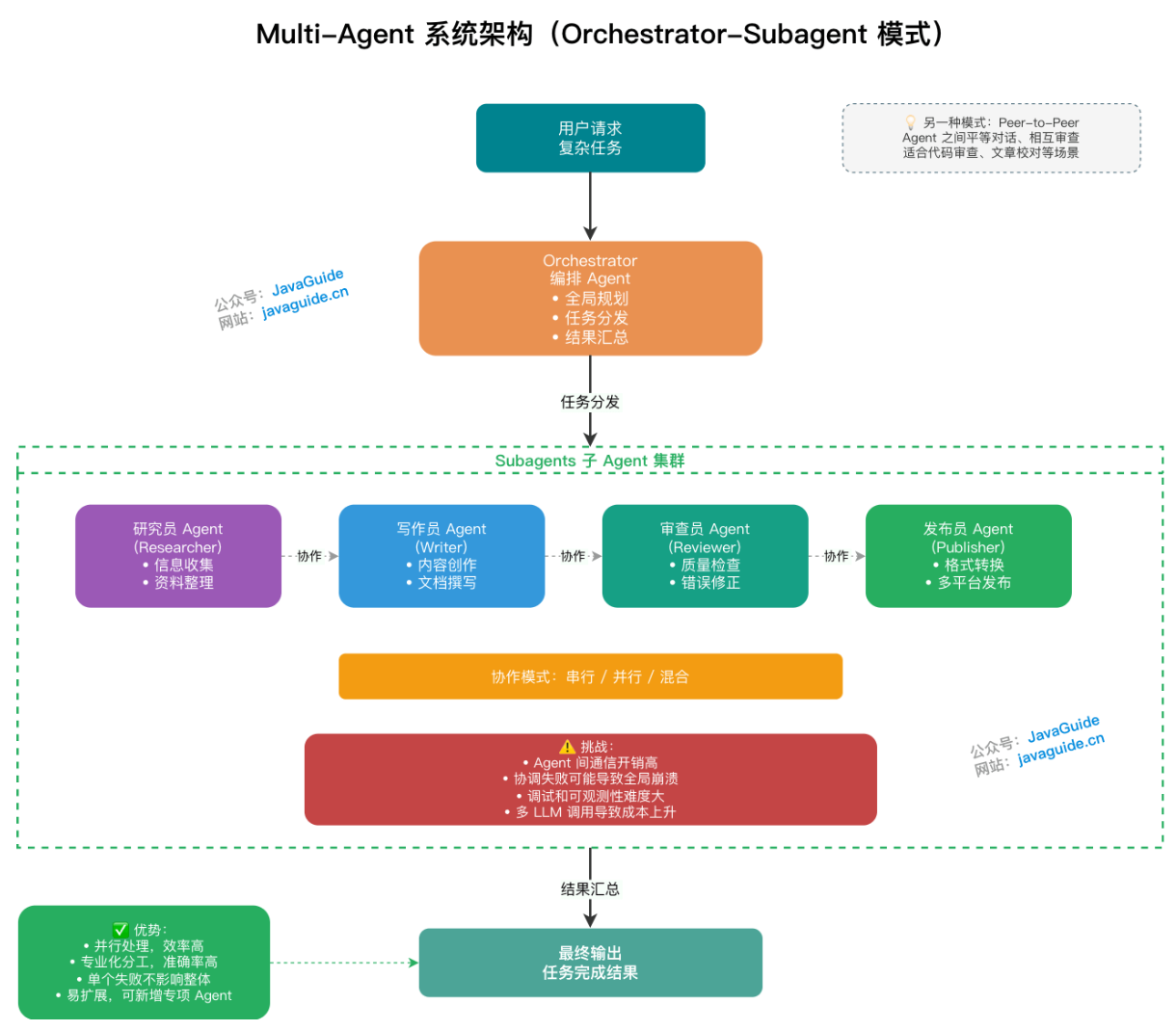
Multi-Agent
- Orchestrator-Subagent 模式(主流):一个编排 Agent(Orchestrator) 负责全局规划和任务分发,多个子 Agent(Subagent) 并行或串行执行具体子任务,最终由 Orchestrator 汇总输出。
- Peer-to-Peer 模式:Agent 之间平等对话、相互审查(如 AutoGen 中的对话式 Agent),适合需要辩论或验证的场景(如代码审查、文章校对)。
![Orchestrator-Subagent 模式]()
A2A通信协议
Agent之间进行通信交互的协议,用Json格式进行高度结构化,带有严格校验规则的数据通信。 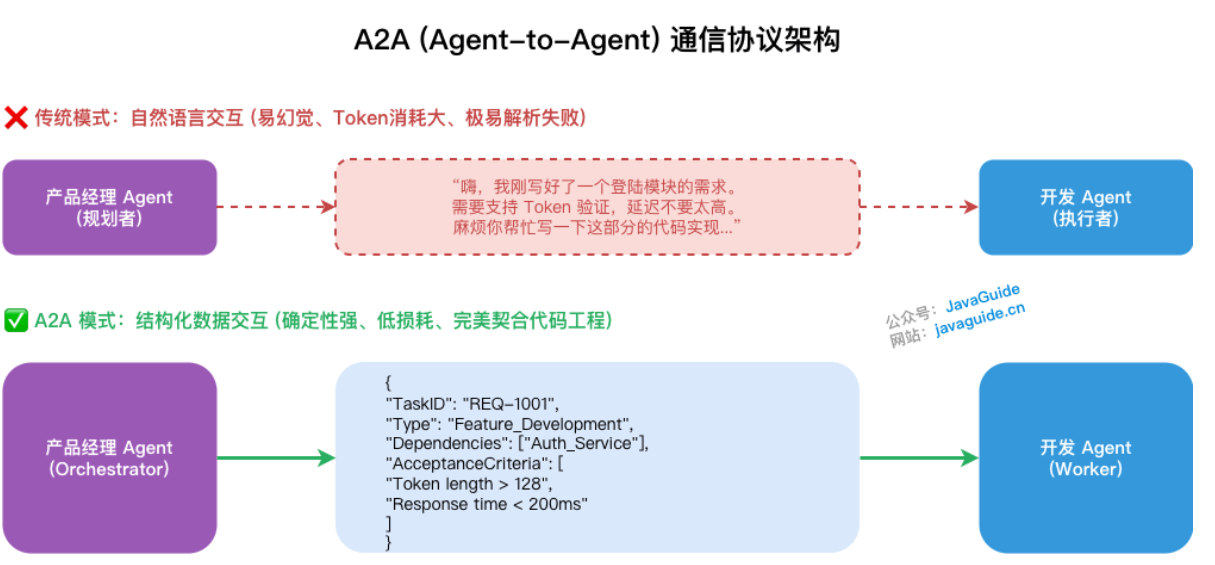
Agentic Workflows(智能工作流)
吴恩达重点倡导的一个宏观概念,实际上是对上述所有范式的终极整合。 Agentic Workflows 涵盖了四大核心设计模式:
- Reflection(反思): 让模型检查自己的工作。
- Tool Use(工具使用): 为 LLM 配备网络搜索、代码执行等工具(即 ReAct 中的 Acting)。
- Planning(规划): 让模型提出多步计划并执行(即 Plan-and-Execute)。
- Multi-agent Collaboration(多智能体协作): 多个不同的 Agent 共同工作。
Agentic Workflows 告诉我们,构建强大的 AI 应用,并不是必须要等 GPT-5 或更底层的参数突破,而是用后端工程的思维,将“推理、记忆、反思、多实体协作”编排成一条流水线。这也是当前 AI 落地应用从“玩具”走向“工业级生产力”的最成熟路径。