1 SubAgent
1.1 概念引入
Agent 工作越久, messages 数组越臃肿。每次读文件、跑命令的输出都永久留在上下文里。”这个项目用什么测试框架?” 可能要读 5 个文件, 但父 Agent 只需要一个词: “pytest”
为了让一个独立可拆分的任务的工作过程不影响父 Agent 的上下文,同时也不让父 Agent 的上下文影响子Agent的工作过程,我们可以使用 SubAgent 来实现。
子智能体的价值,不是“多一个模型实例”本身,而是“多一个干净上下文”,同时子Agent最好只能拥有自己必要的工具,这样能让子Agent专注于自己的任务。
“大任务拆小, 每个小任务干净的上下文” – Subagent 用独立 messages[], 不污染主对话。
Harness 层: 上下文隔离 – 守护模型的思维清晰度
把局部任务放进独立上下文里做,做完只把必要结果带回来。
用处:
- 给父上下文减负
- 让任务描述更清楚
- 让后面的多 agent 协作有基础
1.2 Harness层次
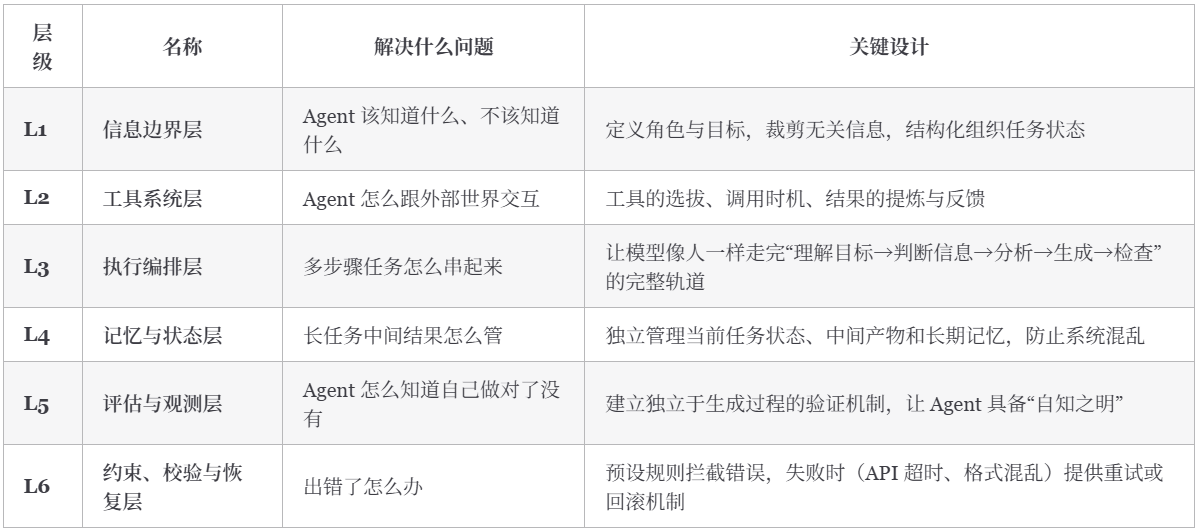
SubAgent不单独属于 Harness 的某一层,同时提供了信息边界层和执行编排层的能力。
1.3 具体实现
实现还是比较简单的。
设计上来看,SubAgent 可以作为一个 Tools 来引入项目。 父Agent拥有 SubAgent 工具,可以调用 SubAgent 来完成任务。 为了避免发生递归生成,子 Agent 不能调用父 Agent 工具。
为此,我们将工具列表分为CHILD_TOOLS和PARENT_TOOLS。这样就能在提示词中向不同的Agent展示不同的工具列表。
1
2
3
4
5
6
7
8
9
PARENT_TOOLS = CHILD_TOOLS + [
{"name": "task",
"description": "Spawn a subagent with fresh context.",
"input_schema": {
"type": "object",
"properties": {"prompt": {"type": "string"}},
"required": ["prompt"],
}},
]
原代码在AgentLoop中判断工具调用了task,然后调用run_subagent方法,实际上就是由父Agent传入一个prompt然后再次创建一个Agent来完成任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def run_subagent(prompt: str) -> str:
sub_messages = [{"role": "user", "content": prompt}]
for _ in range(30): # safety limit
response = client.messages.create(
model=MODEL, system=SUBAGENT_SYSTEM,
messages=sub_messages,
tools=CHILD_TOOLS, max_tokens=8000,
)
sub_messages.append({"role": "assistant",
"content": response.content})
if response.stop_reason != "tool_use":
break
results = []
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input)
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": str(output)[:50000]})
sub_messages.append({"role": "user", "content": results})
return "".join(
b.text for b in response.content if hasattr(b, "text")
) or "(no summary)"
Subagent 可能跑了很多次的工具调用和推理, 但完成后整个消息历史直接丢弃。父 Agent 收到的只是一段摘要文本, 作为普通 tool_result 返回。
1.4 小改进
直接把Agent Loop恢复成通用的tools路由不改动。
改动一下tool dispatch map,将task工具添加到PARENT_TOOLS中。
1
2
3
4
5
6
7
TOOL_HANDLERS = {
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
"task": lambda **kw: run_subagent(kw["prompt"], kw["description"]),
}
改run_subagent方法,添加一个description参数,用于描述子Agent的任务描述,将原本在Loop中进行调试的语句移动到了run_subagent方法中。
1
2
3
def run_subagent(prompt: str, description: str = "subtask") -> str:
print(f"> task ({description}): {prompt[:80]}")
...
2 Skill Loader
2.1 概念引入
不是把所有知识永远塞进 prompt,而是在需要的时候再加载正确那一份。
不同任务需要的领域知识不一样。例如:
- 做代码审查,需要一套审查清单
- 做 Git 操作,需要一套提交约定
- 做 MCP 集成,需要一套专门步骤
- …
如果你把这些知识包全部塞进 system prompt,就会出现两个问题:
- 大部分 token 都浪费在当前用不到的说明上
- prompt 越来越臃肿,主线规则越来越不清楚
把“长期可选知识”从 system prompt 主体里拆出来,改成按需加载就是Skill Loader要做的。
关键概念解释:
- skill: 一份围绕某类任务的可复用说明书。
- discovery: 发现有哪些 skill 可用, 只需要很轻量的信息 (skill 名字, 一句描述)。
- loading: 把某个 skill 的完整正文真正读进来。(昂贵)
在LLM需要一个领域的知识的时候,从提示词中发现自己可用的 skill ,然后调用loading方法加载该 skill 的完整正文。
1
2
3
4
5
6
7
8
9
load_skill("code-review")
|
v
tool_result
|
v
<skill name="code-review">
完整审查说明
</skill>
2.2 Harness 层次
按需知识 – 模型开口要时才给的领域专长。
L1 :信息边界层
2.3 具体实现
我们独立在项目中创建一个 skill 文件夹,里面每个文件夹管理一个领域的 skill,每个领域有一个 SKILL.md 文件(必须,还可以放一些脚本文件),文件内容就是该领域的 skill。
1
2
3
4
5
skills/
code-review/
SKILL.md
git-workflow/
SKILL.md
实现了一个SkillLoader类,封装对SKILL的操作。 为了避免 LLM 调用的时候再进行文件io,我们在初始化SkillLoader时就加载所有 skill 到 skills 字典(内存)中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# -- SkillLoader: scan skills/<name>/SKILL.md with YAML frontmatter --
class SkillLoader:
# 构造函数初始化SkillLoader,记录skill文件夹路径,并加载所有skill到skills字典中 (name -> meta, body, path)
def __init__(self, skills_dir: Path):
self.skills_dir = skills_dir
self.skills = {}
self._load_all()
def _load_all(self):
if not self.skills_dir.exists():
return
for f in sorted(self.skills_dir.rglob("SKILL.md")):
text = f.read_text()
meta, body = self._parse_frontmatter(text)
name = meta.get("name", f.parent.name)
self.skills[name] = {"meta": meta, "body": body, "path": str(f)}
def _parse_frontmatter(self, text: str) -> tuple:
"""Parse YAML frontmatter between --- delimiters."""
match = re.match(r"^---\n(.*?)\n---\n(.*)", text, re.DOTALL)
if not match:
return {}, text
try:
meta = yaml.safe_load(match.group(1)) or {}
except yaml.YAMLError:
meta = {}
return meta, match.group(2).strip()
def get_descriptions(self) -> str:
"""Layer 1: short descriptions for the system prompt."""
if not self.skills:
return "(no skills available)"
lines = []
for name, skill in self.skills.items():
desc = skill["meta"].get("description", "No description")
tags = skill["meta"].get("tags", "")
line = f" - {name}: {desc}"
if tags:
line += f" [{tags}]"
lines.append(line)
return "\n".join(lines)
def get_content(self, name: str) -> str:
"""Layer 2: full skill body returned in tool_result."""
skill = self.skills.get(name)
if not skill:
return f"Error: Unknown skill '{name}'. Available: {', '.join(self.skills.keys())}"
return f"<skill name=\"{name}\">\n{skill['body']}\n</skill>"
SKILLS_DIR = WORKDIR / "skills"
SKILL_LOADER = SkillLoader(SKILLS_DIR)
实现中将一份 Skill 分成了两层,第一层是发现有哪些 skill 可用(元信息),第二层是加载 skill 的完整正文。
1
2
3
4
5
6
7
8
第 1 层: 轻量目录
- skill 名称
- skill 描述
- 让模型知道"有哪些可用"
第 2 层: 按需正文
- 只有模型真正需要时才加载
- 通过工具结果注入当前上下文
对于第一层而言,我们在LLM的系统提示词中调用SkillLoader.get_descriptions告诉模型有哪些skill可用,以及每个skill的简单描述。
1
2
3
4
5
6
# Layer 1: skill metadata injected into system prompt
SYSTEM = f"""You are a coding agent at {WORKDIR}.
Use load_skill to access specialized knowledge before tackling unfamiliar topics.
Skills available:
{SKILL_LOADER.get_descriptions()}"""
对于第二层的实现,复用之前 tools 的设定,将load_skill作为工具引入到项目之中。
1
2
3
4
5
6
7
8
9
10
11
12
TOOL_HANDLERS = {
...,
"load_skill": lambda **kw: SKILL_LOADER.get_content(kw["name"]),
}
TOOLS = [
...,
{"name": "load_skill", "description": "Load specialized knowledge by name.",
"input_schema": {"type": "object", "properties": {"name": {"type": "string", "description": "Skill name to load"}}, "required": ["name"]}},
]
这样LLM就会根据系统提示词披露的skill元信息列表,调用load_skill工具,加载该 skill 的完整正文,以 tool_result 的方式注入到当前上下文。